Today i will teach you in Understanding Three-way Interaction in ANOVA
Consider the three-way ANOVA, shown below, with a significant three-way interaction. There are 24 observations in this analysis. In this model a has two levels, b two levels and c has three levels. You will note the significant three-way interaction. Basically, a three-way interaction means that one, or more, two-way interactions differ across the levels of a third variable. In this page, we will show you the steps that are involved and work through them manually.
For the purposes of this example we are going to focus on the b*c interaction and how it changes across levels of a.
Source | Partial SS df MS F Prob > F
-----------+----------------------------------------------------
a | 150 1 150 112.50 0.0000
b | .666666667 1 .666666667 0.50 0.4930
c | 127.583333 2 63.7916667 47.84 0.0000
a*b | 160.166667 1 160.166667 120.13 0.0000
a*c | 18.25 2 9.125 6.84 0.0104
b*c | 22.5833333 2 11.2916667 8.47 0.0051
a*b*c | 18.5833333 2 9.29166667 6.97 0.0098
|
Residual | 16 12 1.33333333
-----------+----------------------------------------------------
Total | 513.833333 23 22.3405797
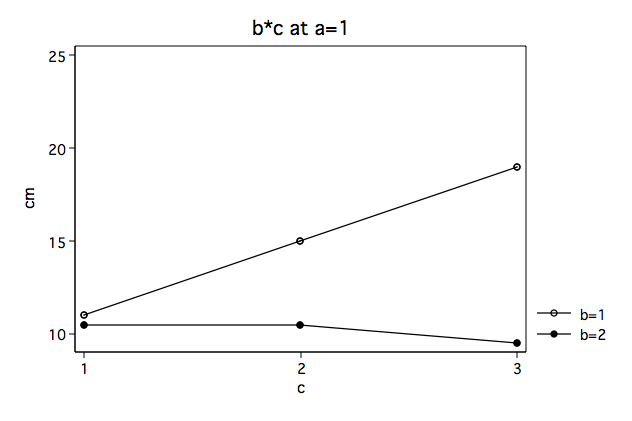
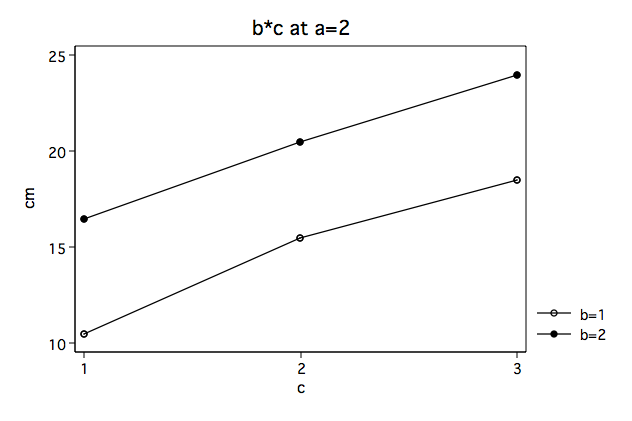
In looking at the plots (above) it appears that the b*c interaction looks very different at the two levels of a. We suspect that there is a significant interaction at a=1 but that the interaction is not significant at a=2. So we need to be able to provide some statistical evidence to back this suspicion up.
We will start by running an ANOVA with just b and c for those cases in which a=1.
Source | Partial SS df MS F Prob > F
-----------+----------------------------------------------------
b | 70.0833333 1 70.0833333 56.07 0.0003
c | 24.6666667 2 12.3333333 9.87 0.0127
b*c | 40.6666667 2 20.3333333 16.27 0.0038
|
Residual | 7.5 6 1.25
-----------+----------------------------------------------------
Total | 142.916667 11 12.9924242
There is a problem in the above table. The F-ratio in the table is wrong. The reason that the F-ratio is wrong is that it uses the wrong error term (residual). It is using an error term based on just 6 degrees of freedom and not on the 12 degrees of freedom found in the original model. We should be using the mean square residual from the original three-factor model. We need to recompute the F-ratio using the the mean square residual equal to 1.33333333. Here is the correct computation for the F-ratio.
F(2, 12) = MS(b*c)/MS(residual) = 20.3333333/1.33333333 = 15.25
Next, we will repeat the process for a=2 including the manual computation of the F-ratio.
Source | Partial SS df MS F Prob > F
-----------+----------------------------------------------------
b | 90.75 1 90.75 64.06 0.0002
c | 121.166667 2 60.5833333 42.76 0.0003
b*c | .5 2 .25 0.18 0.8424
|
Residual | 8.5 6 1.41666667
-----------+----------------------------------------------------
Total | 220.916667 11 20.0833333
F(2, 12) = MS(b*c)/MS(residual) = .25/1.33333333 = .1875
